What is Reinforcement Learning?
Short answer
Reinforcement learning (RL) is an optimization framework.
Long answer
A problem can be considered a reinforcement learning problem if it can be framed in the following way: Given an enviroment in which an agent can take actions, receiving a reward for each action, find a policy that maximizes the expected cumulative reward that the agent will obtain by acting in the environment.
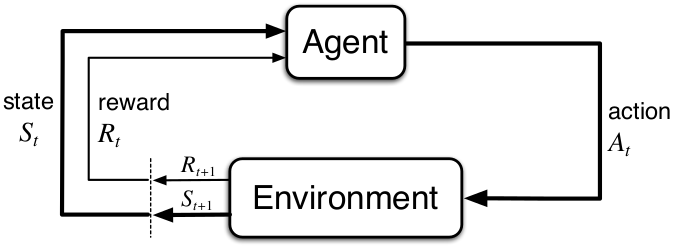
Markov Decision Processes
The most famous mathematical structure used to represent reinforcement learning environments are Markov Decision Processes (MDP). (Bellman1957) introduced the concept of a Markov Decision Process as an extension of the famous mathematical construct of Markov chains. Markov Decision Processes are a standard model for sequential decision making and control problems. An MDP is fully defined by the 5-tuple . Whereby:
-
is the set of states of the underlying Markov chain, where represents the state of the environment at time .
-
is the set of actions which are the transition labels between states of the underlying Markov chain. is the subset of available actions in state at time . If an state has no available actions, it is said to be a \textit{terminal} state.
-
, where , . is the transition probability function (The function is also known in the literature as the transition probability kernel, or the transition kernel. The word kernel is a heavily overloaded mathematical term that refers to a function that maps a series of inputs to value in ). It defines the probability of transitioning to state from state after performig action . Thus, . Given a state and an action at time , we can find the next state by sampling from the distribution .
-
, where , . is the reward function, which returns the immediate reward of performing action in state and ending in state . The real-valued reward (The reward can be equivalently written as ) is typically in the range . . If the environment is deterministic, the reward function can be rewritten as because the state transition defined by is deterministic.
-
is the discount factor, which represent the rate of importance between immediate and future rewards. If the agent cares only about the immediate reward, if all rewards are taken into account. is often used as a variance reduction method, and aids proofs in infinitely running environments (Sutton 1999).
The environment is sometimes represented by the Greek letter . The tuple of elementes introduced above are the core components of any environment . Finally, a lot of work in RL literature also presents a distribution over initial states of the MDP, So that the initial state can be sampled from it: .
An environment can be episodic if it presents terminal states, or if there are a fixed number of steps after which the environment will not accept any more actions. However environments can also run infinitely.
Acting inside of the environment, there is the agent, and through its actions the transitions between the MDP states are triggered, advancing the environment state and obtaining rewards. The agent’s behaviour is fully defined by its policy . A policy , where , is a mapping from states to a distribution over actions. Given a state it is possible to sample an action from the policy distribution . Thus, .
The reinforcement learning loop presented in image above can be represented in algorithmic form as follows:
- Sample initial state from the initial state distribution
- .
Repeat until - Sample action
- Sample successor state from the transition probability function
- Sample reward from reward function
For an episode of length , The objective for the agent is to find an optimal policy , which maximizes the cumulative sum of (possibly discounted) rewards.
Time for References!
Bellman. 1957. A Markovian decision process
Richard Sutton, Barto. 1999. Reinforcement learning: An introduction.
Hessel, Matteo Modayil, Joseph van Hasselt, Hado. 2017. Rainbow: Combining Improvements in Deep Reinforcement Learning.